Vom 09. bis zum 12. Dezember fand in Los Angeles die 2019 IEEE International Conference on Big Data statt. Für das titan-Projekt hat Sören Henning, wissenschaftlicher Mitarbeiter der Universität Kiel, an der Konferenz teilgenommen und Ergebnisse des Projekts auf dem 4th Workshop on Real-time & Stream Analytics in Big Data & Stream Data Management präsentiert.
Während draußen weihnachtliche 18 °C und klarster Sonnenschein herrschten, wurde im Westin Bonaventure Hotel über Stream Processing Architekturen, Data Pipelines und Echtzeit-Algorithmen diskutiert. Besonders hervorgehoben von den Organisatoren wurde dabei, dass es in diesem Jahr besonders viele Einreichungen zu den Themen Internet of Thing (IoT) und Industrie 4.0 gab – also Themen, die wir auch im titan-Projekt adressieren.
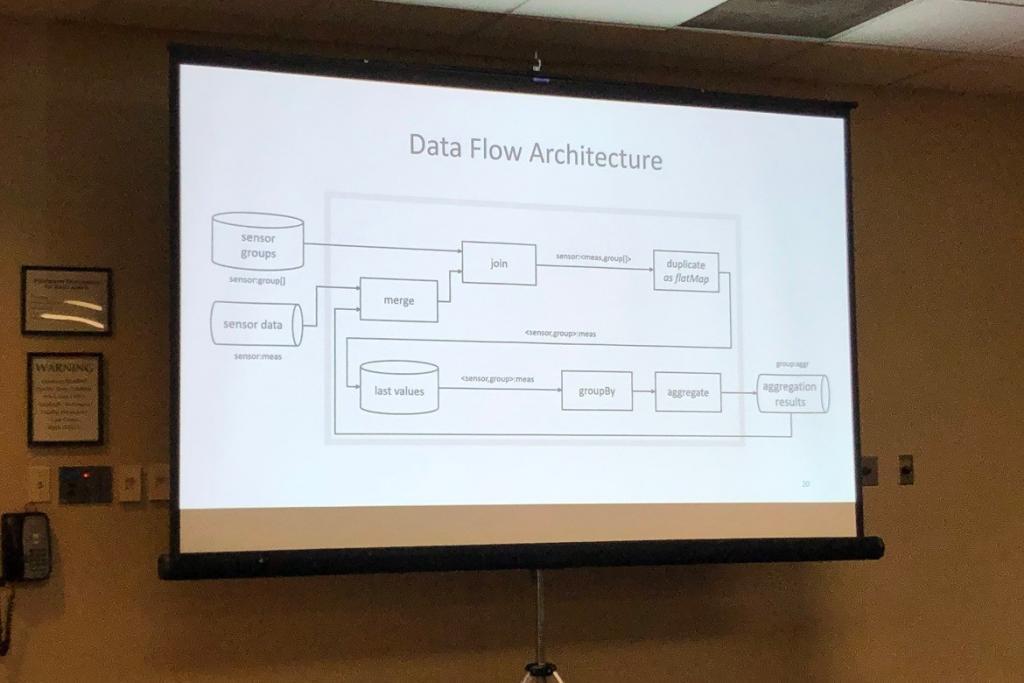
So passte unserer Vortrag Scalable and Reliable Multi-Dimensional Aggregation of Sensor Data Streams, in dem wir eine Datenflussarchitektur, die Messdaten von unterschiedlichen Sensoren kontinuierlich und in Echtzeit aggregiert, vorgestellt haben, auch sehr gut ins Programm. Der Bedarf für eine solche Aggregation stammt direkt von den im titan-Projekt assoziierten Partnern, die unter anderem die Stromverbräuche von einzelnen Maschinen und Geräten in der Produktion aggregieren wollen, um so zu erkennen, welche Art von Maschinen in welchem Maße zum Gesamtstromverbrauch beitragen. Wir konnten daher unseren Ansatz mit reellen Daten der assoziierten Partnern evaluieren. Weiterhin haben wir die Ergebnisse experimenteller Evaluationen vorgestellt, in denen wir nachweisen konnten, dass unser Ansatz mit der Menge an Sensoren skaliert und verlässlich funktioniert auch im Falle von Ausfällen der Infrastruktur.
Zu unserer vorgestellten Lösung haben wir sehr viel positive Rückmeldungen erhalten. Dabei gab es Übereinstimmung darin, dass ein solcher Aggregationsansatz notwendig ist und das aktuelle Big-Data-Streaming-Lösungen nur unzureichende Unterstützung für einen Anwendungsfall bereitstellen. Da auch Software-Ingenieure entsprechender Systeme, wie zum Beispiel Apache Kafka, am Workshop teilnahmen, konnte mit ihnen erörtert werden, welche zukünftigen Entwicklungen hier notwendig sind. Auch unser Anwendungsfall, die Analyse von Stromverbrauchsdaten in der industriellen Produktion, stieß auf großes Interesse.
Ein Preprint unseres präsentierten Papiers haben wir auf arXiv veröffentlicht: Scalable and Reliable Multi-Dimensional Aggregation of Sensor Data Streams
Ein ausführlicher Bericht über den Workshop findet sich bei Eura Nova.